Download
Videos at ACM MM'2022

Analysis
GitHub Repo
|
|
|
|
|
|
|
|
|
|
|
|
Download |
Videos at ACM MM'2022 |
Analysis |
GitHub Repo |
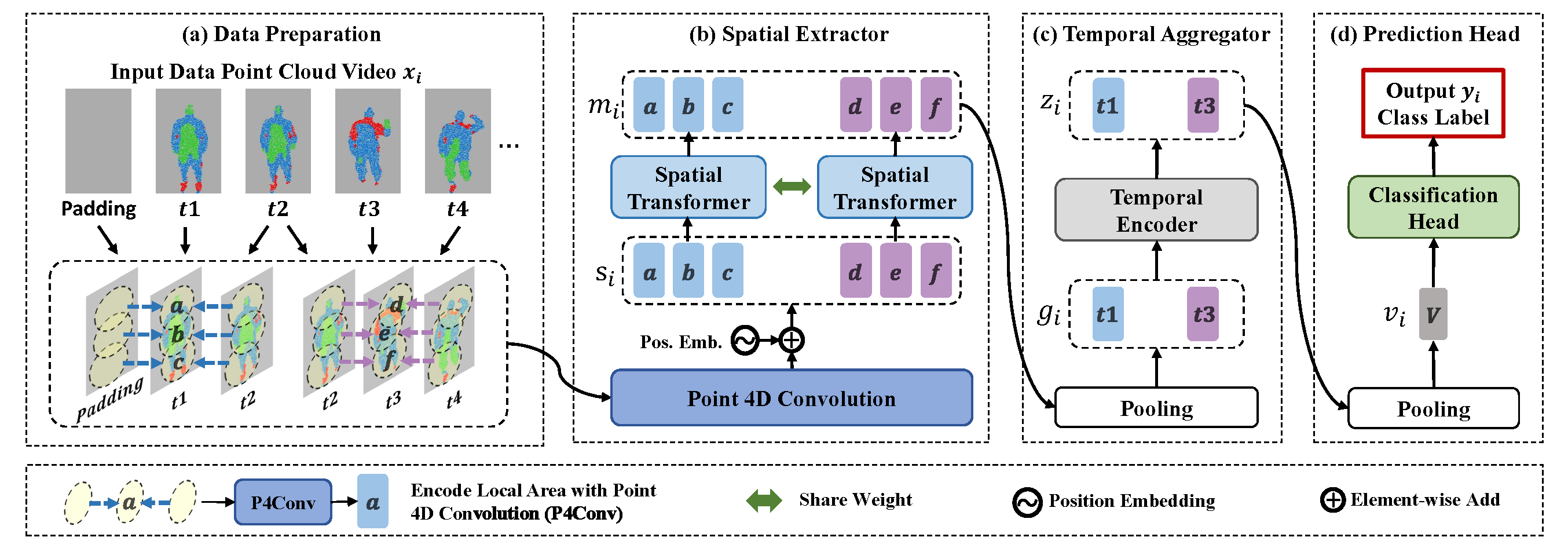 |
The detail of DestFormer.
(a) Data Preparation: we construct some local areas (e.g. ``a'') on adjacent frames (e.g. ``t1'', ``t2'') from the input `x_i` as what P4Conv do.
(b) Spatial Extractor: we adopt P4Conv for modeling short-time local information and feed the output `s_i` frame by frame into a spatial transformer for extracting the merged local feature `m_i`.
(c) Temporal Aggregator: we generate the short-term global feature `g_i` through the pooling layer and aggregate the long-term global information with the temporal encoder.
(d) Prediction Head: we project the global feature `v_i` into label space via the classification head.
|
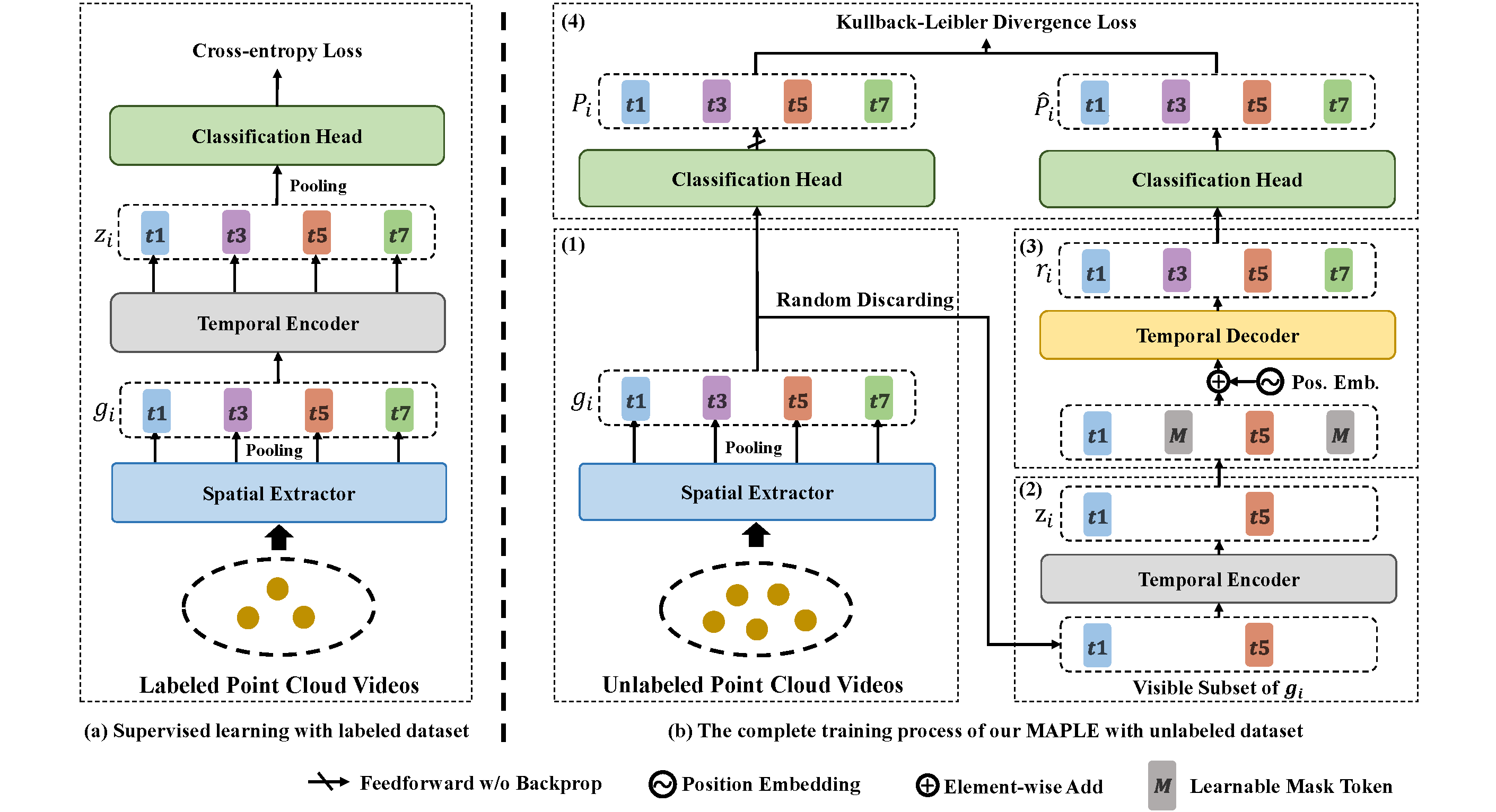 |
The detail of our MAPLE.
(a) Adopting our DestFormer backbone and the cross-entropy loss for the supervised training.
(b) The complete training process of MAPLE:
(1) The spatial extractor encodes the input video as the short-term global feature `g_i`.
(2) After randomly discarding the short-term global feature `g_i`, the temporal encoder projects the visible subset of `g_i` as the latent representation `z_i`.
(3) The temporal decoder is responsible for reconstructing `r_i` from the latent representation `z_i` and the mask tokens `M`.
(4) The classification head generates the pseudo-label `P_i` and `\hat{P}_i` as our reconstruction target. Note that the modules here with the same colors share weights.
|
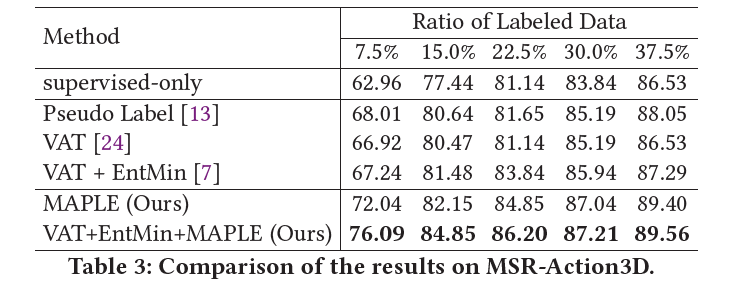 MSR-Action3D |
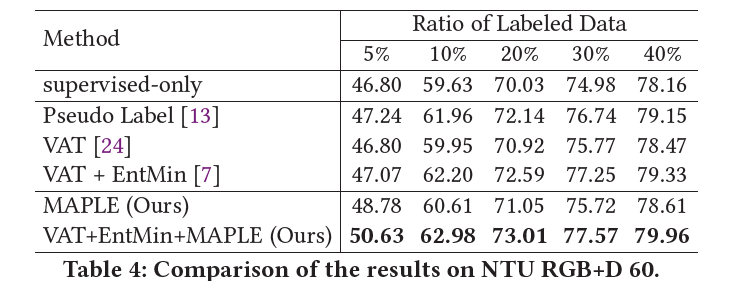 NTU RGB+D 60 |
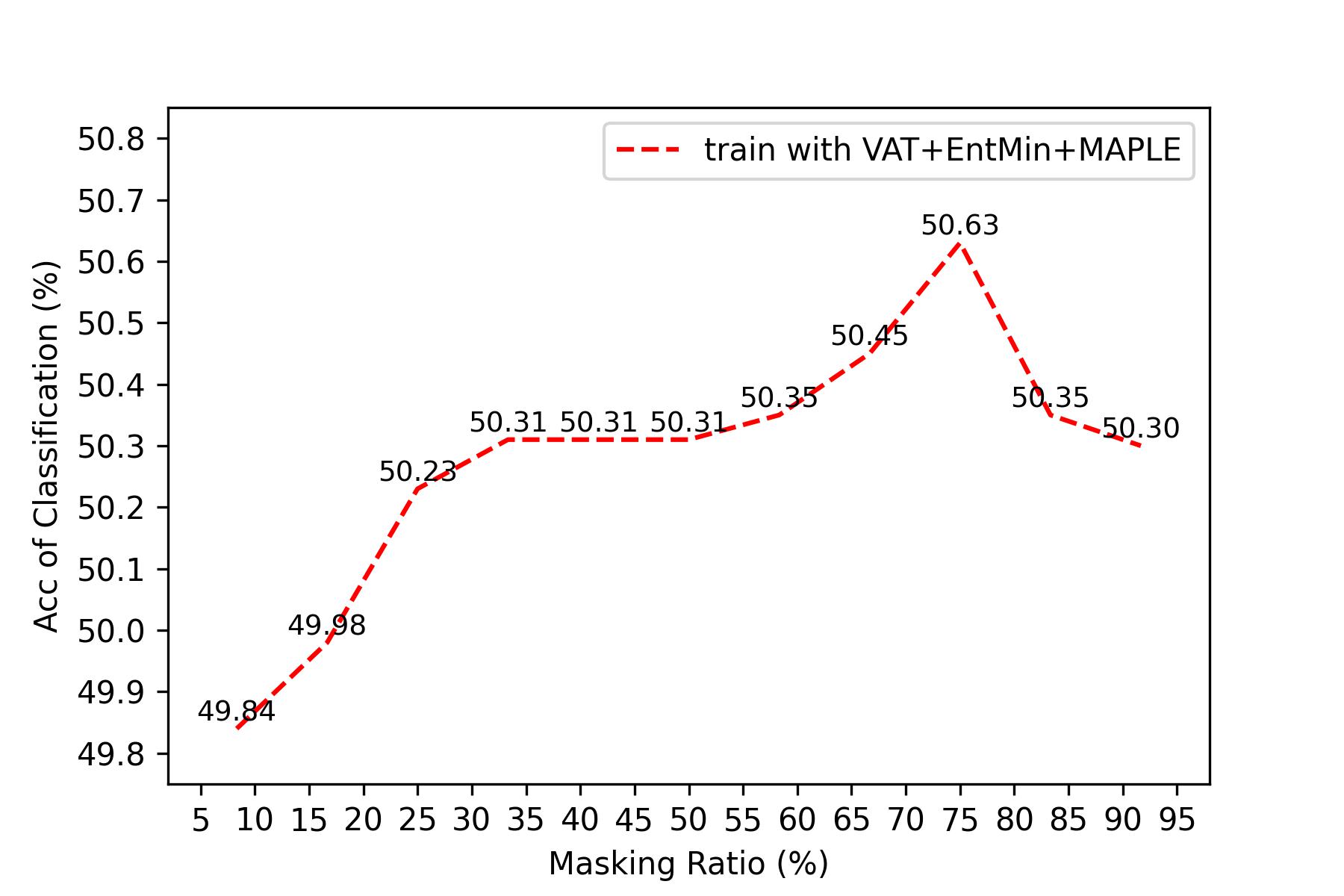 The accuracy of classification on NTU RGB+D 60 5% labeled dataset with different masking ratios. |
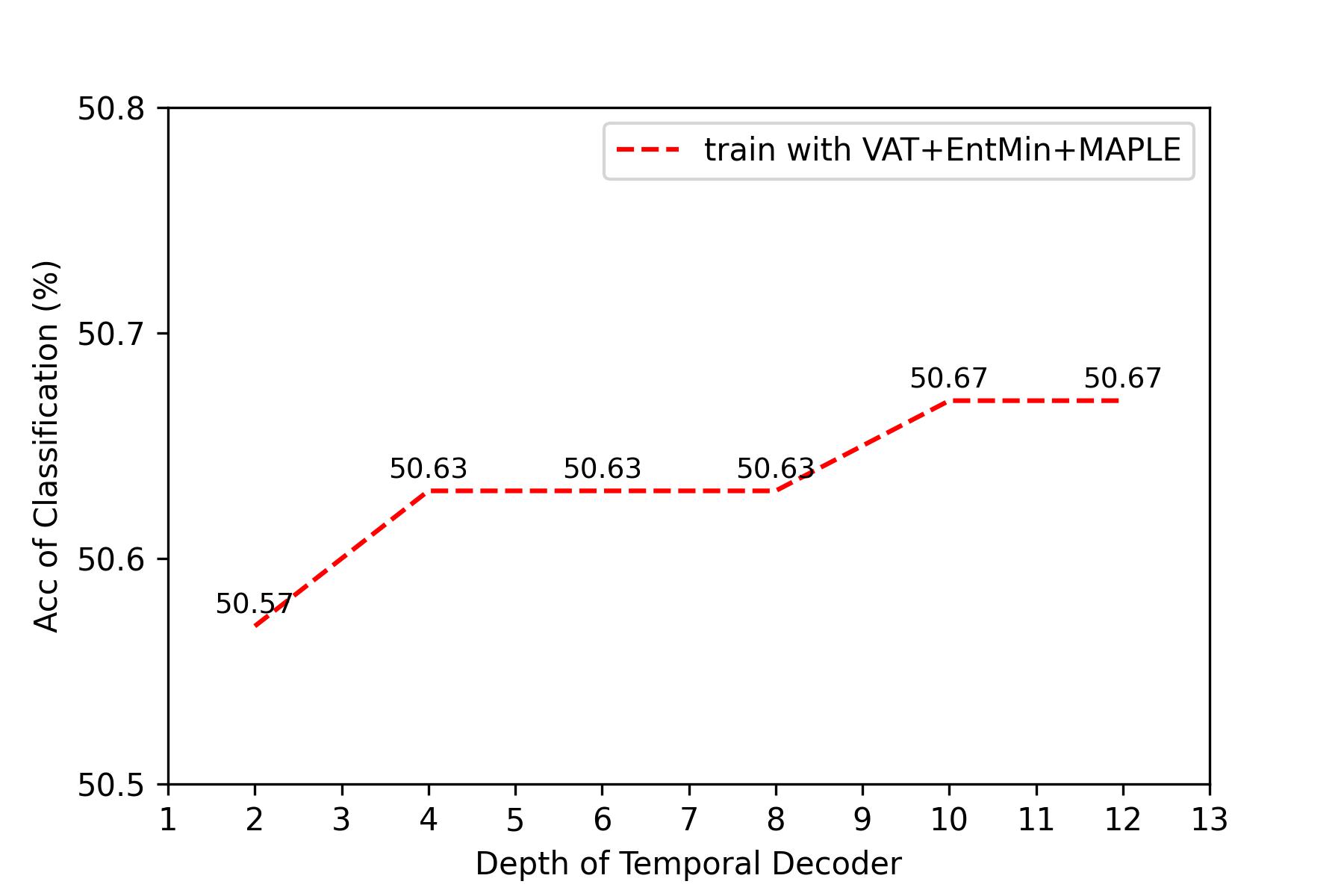 The accuracy of classification on NTU RGB+D 60 5% labeled dataset with different depth of temporal decoder. |
|
MSR-Action3D NTU RGB+D 60 NTU RGB+D 120 |
 |
Chen, Liu, Liu, Zhang, Zhang, Han, Mei. MAPLE: Masked Pseudo-Labeling autoEncoder for Semi-supervised Point Cloud Action Recognition In ACM MM, 2022 (Poster). (arXiv) |
AcknowledgementsThis work was done when Xiaodong Chen was an intern at JD AI Research. |
Contact |